1 背景
在之前,网络节点的表示学习还是一个不温不火的领域。深度学习在图像、语音、自然语言处理取得巨大成功后,网络节点的表示学习受到了更多的关注。将网络节点进行向量化表示后,可以方便地作为深度学习模型的输入。现在,网络节点的表示学习已经应用于链接预测、传播分析、跨平台身份映射等领域。
比较成熟的网络节点算法包括:DeepWalk、LINE、node2vec等。这些方法都可以看成是词向量(word embedding)的推广。
2 DeepWalk
DeepWalk[1]的思想简单直接:在图上随机游走,产生T个序列,将这T个序列看成是文档,然后使用Word2vec训练向量表示。整个步骤为:
-
在网络上随机选取一个节点作为初始节点vi;
-
在当前节点的邻居节点中随机选取一个节点作为下一个节点;
-
如果访问节点数大等于给定最大步数T,那么将访问过的节点作为一个序列输出;否则,回到(2)继续随机游走。
-
重复1-3的随机游走过程,直到产生T个随机游走序列。
-
将T个游走序列看成文档,使用Word2vec训练网络节点的向量表示。
代码参考:https://github.com/phanein/deepwalk
3 LINE
LINE[2]不使用随机游走进行采样,而是直接使用节点之间的关系构造目标函数。它的目标函数包括两个部分:
(1)LINE with First-order Proximity
这一个目标函数只能用于无向图。
假设,对于每一个边(i, j),两个节点之间的连接概率与节点对应的向量满足:
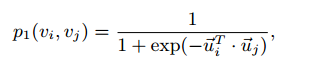
进一步假设,(i,j)之间连接概率的经验值为:
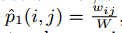
使用KL散度作为优化目标,忽略常数W,得到:
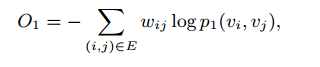
(2)LINE with Second-order Proximity
这个目标函数可以用于有向图。
假设给定节点i时产生节点j的概率为:
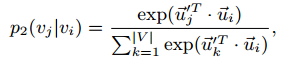
使用经验值
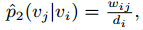
这里,wij表示(i,j)之间的边权重,di是i节点的度。
同样使用KL散度作为目标函数,论文中对di进行了简化,得到函数为:
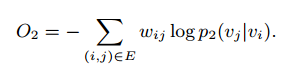
与Word2vec相同,使用NCE(Noise Contrastive Estimation),即负采样的方法来减少计算量。

负采样的概率分布
由于在优化过程中,
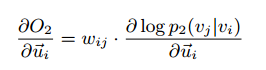
学习过程受到了wij的影响,如果wij过大,会产生过大的梯度,太小则对目标函数的优化没有作用。因此,文章中提出使用Edge sampling的方法,即从有权边里面根据权重进行随机采样,每次采样得到一个权重固定为1的边。使用alias table method,采样时间为O(1)的复杂度。
代码参考:https://github.com/tangjianpku/LINE
4 node2vec
node2vec[3]在Deepwalk上做了一些改动。随机游走过程中,下一个节点不再是当前节点的邻居节点中随机选取一个;而是根据与上一节点是否相连有不同的概率。
具体地,如果与上一个节点有连接,那么权重为1,上一个节点的权重为1/p,其他节点的权重为1/q,正规化成和为1的概率值。将这个不均匀分布的概率值作为下一个节点的采样概率。
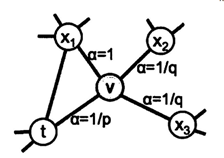
p和q的解释:作者在文章解释,如果p很大,那么随机游走过程将会不倾向于采样已经访问过的节点。而如果p很小,那么随机游走过程会倾向于采样未访问过的节点,那么游走过程会集中在初始节点附近。如果q>1,那么随机游走过程会倾向于访问局部的一些节点,类似于BFS的方式。而如果q<1,则随机游走过程会倾向于远离t,采样一种类似DFS的方式进行随机游走。
进一步的案例分析发现,当p=1,q=0.5时,node2vec发现的是社区特性。而p=1,q=2时,node2vec学习到的是结构特性,例如将一些桥聚成一个类别。
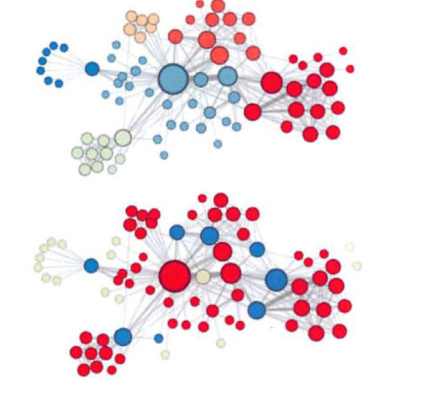
代码中同样使用了LINE中的alias table method进行计算采样概率。但是如果预先计算alias table需要存储每个2-hop的路径。这在超大规模且连接较为紧密的网络上将会耗费很大的空间。
代码:http://snap.stanford.edu/node2vec
5 向量表示的评价
在这些文章中,网络节点的向量表示的评价通常使用以下几种方法:(1)链接预测:使用一部分网络边训练向量表示,使用训练好的向量来预测其他的边。(2)分类任务:在社交网络或者文本构造的网络上训练向量表示,将训练好的向量作为特征进行分类。(3)可视化。
参考文献
[1] Perozzi, Bryan, Rami Al-Rfou, and Steven Skiena. “Deepwalk: Online learning of social representations.”?Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014.
[2] Tang, Jian, et al. “Line: Large-scale information network embedding.”?Proceedings of the 24th International Conference on World Wide Web. ACM, 2015.
[3] Grover, Aditya, and Jure Leskovec. “node2vec: Scalable feature learning for networks.”?Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016.
47 评论