-
背景
生成对抗网络(Generative Adversarial Network, GAN)是目前性能最好的生成模型,由lan
Goodfellow在2014年提出。目前在图像、自然语言处理领域都取得了非常好的效果。深度学习大牛Yann Lecun称它为”10年来机器学习领域最酷的想法”。代码地址(基于Tensorflow):
(1)简单正态分布数据:https://github.com/AYLIEN/gan-intro(2)MNIST: https://github.com/yihui-he/GAN-MNIST
-
模型简介
生成模型通过学习数据(例如人脸图像)的分布,然后自动生成新的数据(一个新的人脸图像)。
GAN模型分为两个部分,一个是generator,用于生成新的数据;一个是discriminator,用于判别数据是真实数据还是generator生成的。generator与discriminator之间互相博弈,generator试图产生能够骗过discriminator的数据,而discriminator则试图将生成的数据与真实数据区分开。相关研究表明这种训练方式,可以产生min-max的零和结果。
一般来说generator以及discriminator都是神经网络模型。
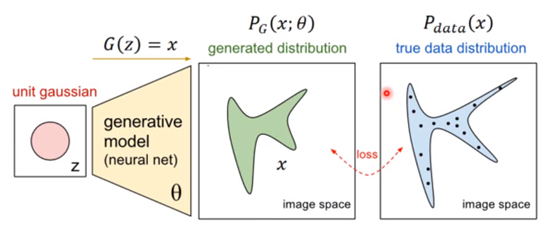
以一个图像生成模型为例。generator的输入时一个随机向量z,通过矩阵乘法与反卷积操作,将z映射为一个图像,即一个3维张量或者矩阵。这个generator所产生数据的概率分布记为
 。真实数据的概率分布记为
。真实数据的概率分布记为 。discriminator的输入是一个图像,而输出则是在[0,1]的概率值,表示该图像是真实图像的概率,它可以是任何图像分类模型。discriminator可以记为一个函数D(x)。
。discriminator的输入是一个图像,而输出则是在[0,1]的概率值,表示该图像是真实图像的概率,它可以是任何图像分类模型。discriminator可以记为一个函数D(x)。
GAN的目标函数可以记为:
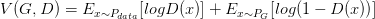
对于discriminator,这个目标函数的前半部分表示discriminator对真实图像输出的判断正确所产生的目标函数值,后半部分表示discriminator对于生成图像的判断错误所产生的目标函数值。
整个训练的过程就是寻找使得目标函数最小的生成模型,以及使得目标函数最大的判别模型。
可以看出generator的损失函数其实是通过discriminator得到的。这种依赖关系使得如果discriminator很好的区分真实数据与生成数据,目标函数和梯度接近于零,很难通过梯度下降进行训练。另外,优化过程损失函数值会出现震荡。
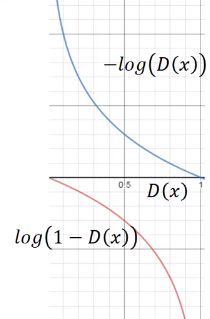
为了解决GAN难以优化的问题,相关研究提出了一些解决方案,一个是discriminator与generator交替训练;一个是使用minibatch进行训练。一些深度学习的技巧也加入其中,如:使用stride convolution代替pooling(池化);使用batch normalization;移除全连接,使得能训练更深的模型;使用ReLU、LeakyReLU激活函数。
-
实验结果
简单正态分布的结果
对于一个正态分布的GAN模型结果:
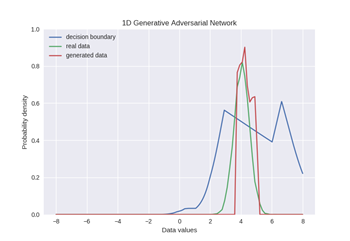
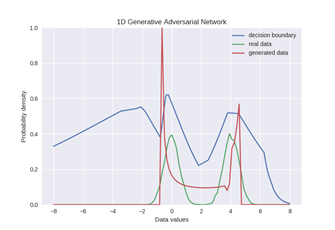
对于混合高斯模型的GAN模型训练结果:
MNIST数据上的结果
训练100个图像的时候,GAN生成的图像为:

生成的图像十分模糊,只能看到依稀生成了一些数字。
训练到6700步的时候,GAN生成的图像为:

可以看出生成的图像已经比较清晰了,只是仍然有些图像的笔画很不连贯。
训练到19400步的时候:

大部分的图像都非常清晰了。
-
一些理论分析
普通生成模型的优化目标
对于一个真实数据
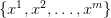 ,生成模型产生这些数据的概率为
,生成模型产生这些数据的概率为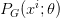 。生成模型中的似然就是
。生成模型中的似然就是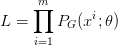 。如果将真实数据的概率分布也考虑进来,那么似然函数可以改写为:
。如果将真实数据的概率分布也考虑进来,那么似然函数可以改写为:
![\[=\int_{x \in X}P_{data}(x)\log P_{data}(x) - P_{data}(x)\log P_G(x)dx\]](http://www.hackcha.cn/wp-content/ql-cache/quicklatex.com-a4e5ff5a99a17eb7b402a4ba617d9201_l3.png "Rendered by QuickLaTeX.com")
![\[=\int_{x\in X} P_{data}(x) \log \frac{P_{data}(x)}{P_G(x)} dx\]](http://www.hackcha.cn/wp-content/ql-cache/quicklatex.com-06ff5e56575d6ed4894bd6056752d68d_l3.png "Rendered by QuickLaTeX.com")
![\[=KL(P_{data}||P_G)\]](http://www.hackcha.cn/wp-content/ql-cache/quicklatex.com-f592ccd46d2501cf3ca18182be7343f4_l3.png "Rendered by QuickLaTeX.com")
给定真实数据分布的情况下,这个式子的前半部分可以看成一个常数,而
 中才包含需要优化的参数。后面的部分是将生成模型对于真实数据的概率值取log,然后将
中才包含需要优化的参数。后面的部分是将生成模型对于真实数据的概率值取log,然后将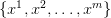 看成对真实数据概率分布的采样数据,使用更加泛化的形式,将L看成是在真实概率分布下的均值。
看成对真实数据概率分布的采样数据,使用更加泛化的形式,将L看成是在真实概率分布下的均值。
可以看成普通的目标函数就是一个KL-divergence。这个函数有几个缺点:
(1)当
 ,
, 的时候,这个目标函数会趋向于无穷大。因此生成模型没有覆盖的真实数据,会产生很大的目标函数值。
的时候,这个目标函数会趋向于无穷大。因此生成模型没有覆盖的真实数据,会产生很大的目标函数值。(2)
 ,
, 时,目标函数为0。生成的假数据对目标函数几乎没有生成影响。
时,目标函数为0。生成的假数据对目标函数几乎没有生成影响。
(3)另外就是如果使用简单的生成模型,会产生Mode Collapse的问题(实际上,原始的GAN训练方法会产生更严重的Mode Collapse,甚至只会生成某一个真实图像),如下图,使用一个正态分布来拟合双峰概率分布:

因此,单纯的使用最大似然函数会产生很大的问题。
GAN的优化目标
想要最大化似然函数,等价于让generator生成那些真实图片的概率最大。这就变成了
所以最大化似然,让generator最大概率的生成真实图片,也就是要找一个
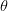 让
让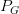 更接近于
更接近于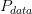 。
。
而对于GAN,我们先固定G,来求解最优的D

求解得到:

对于一个给定的x,得到最优的D如上图,范围在(0,1)内,把最优的D带入
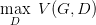 ,可以得到:
,可以得到:
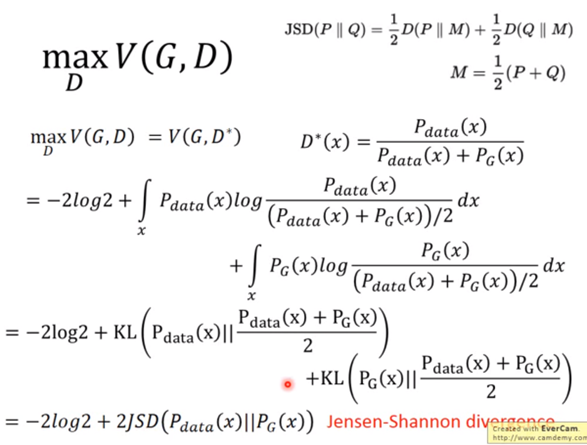
JS divergence是KL divergence的对称平滑版本,表示了两个分布之间的差异,这个推导就表明了上面所说的,固定G,
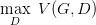 表示两个分布之间的差异,最小值是-2log2,最大值为0。
表示两个分布之间的差异,最小值是-2log2,最大值为0。
现在我们需要找个G,来最小化
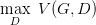 ,观察上式,当
,观察上式,当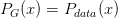 时,G是最优的。
时,G是最优的。
相关研究表明,GAN产生更加真实图像的原因就在于优化目标的改变。
训练过程产生的问题
实际上,如果discriminator产生过拟合,会使得传递到生成器的梯度非常小。

对于这个问题,我们是否应该让D变得弱一点,减弱它的分类能力,但是从理论上讲,为了让它能够有效的区分真假图片,我们又希望它能够powerful,所以这里就产生了矛盾。
还有可能的原因是,虽然生成模型与实际数据这两个分布都是高维的,但是两个分布都十分的窄,可能交集相当小,这样也会导致JS divergence算出来等于log2,约等于没有交集。而最可怕的时候,一般来说真实数据都在高维空间中,因此很大概率会出现生成模型与实际数据这两个分布交集非常小。
解决的一些方法,有添加噪声,让两个分布变得更宽,可能可以增大它们的交集,这样JS divergence就可以计算,但是随着时间变化,噪声需要逐渐变小。最新的解决方案是WGAN模型。
-
总结
GAN模型可以生成高质量的图像,通过加入一个可控变量c,还可以指定生成图像的类别。但是GAN模型的训练速度、收敛性还是有比较大的问题。在训练过程中,经常会出现在一个损失值附近震荡。目前GAN已经在图像分类、图像分割、图像清晰化、古诗词生成、信息检索等任务中得到应用。
-
参考文献
[1] Radford A, Metz L, Chintala S. Unsupervised Representation with Deep Generative Adversarial Networks[J]. Science, 2015.
[2] Arjovsky M, Bottou L. Towards Principled Methods for Generative Adversarial [J]. 2017.
生成对抗网络GAN模型简介