1简介
Image caption最近十分火,coco以及AI challenge中都包含了这个任务。给定一个图片,如何让机器自动生成相应的句子描述?这需要算法对图像以及自然语言有一定的理解能力,因此,Image caption是一个十分困难的任务。目前最有效的模型是基于encoder-decoder的end2end模型。Google提出的NIC(neural image caption)引领了这个研究热潮,随后提出的模型大部分都是在NIC基础上的改进。例如:加入注意力机制、加入图像object信息、以及使用强化学习进行更好的文本生成。
2模型
2.1 NIC模型
NIC模型[1]是Image caption中的经典模型。
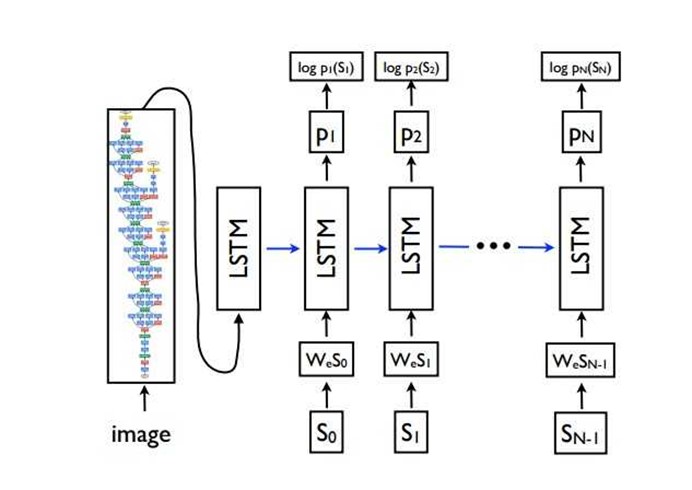
模型的结构建档清晰,首先是用encoder将图片映射为一个向量表示,模型中使用的是Inception v3。然后想图片向量I,作为一个RNN的初始化状态,RNN一步一步的生成caption单词,每一步都使用上一步生成的单词作为输入,直到生成特殊字符EOS时完成caption的生成。
2.2 Attention模型
在Attention模型[2]中,将图片分为L个部分,例如VGG生成的14*14*256的图片特征,可以视为196个位置。图片的特征可以表示为 。在Decoder生成caption的过程中,每个时刻(假定为t),都产生一个长度L的attention权重向量,
。在Decoder生成caption的过程中,每个时刻(假定为t),都产生一个长度L的attention权重向量, 表示t时刻,图片第i个位置的注意力权重,通过图片特征一个RNN的状态计算得到。值得注意的是后来一些研究中直接使用当前时刻的状态而不是这里的上一时刻的状态来计算注意力权重。
表示t时刻,图片第i个位置的注意力权重,通过图片特征一个RNN的状态计算得到。值得注意的是后来一些研究中直接使用当前时刻的状态而不是这里的上一时刻的状态来计算注意力权重。
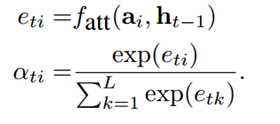
在hard attention中,直接通过从multinomial分布中选取一个图片区域的特征作为生成当前单词的输入。利用蒙特卡洛算法进行参数优化。而在soft attention中,利用注意力权重对各个区域的图片特征进行加权求和,进而作为生成当前单词的图片特征。Soft attention可微,因此更容易优化。
论文中进行case study,可以看出模型的可解释性很强,可以很容易分析错误的源头。

另外,还有一篇文章[3]认为,生成单词序列的过程中并不是每个时刻都需要图片信息,因此,提出了一个visual sentinel(视觉哨兵)的概念,使用一个向量 来表示encoder已经知道的信息,假定图片的信息为
来表示encoder已经知道的信息,假定图片的信息为 ,那么可以用
,那么可以用
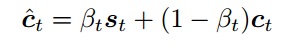
作为产生单词的特征输入。
下面的图片可以清晰的看出该模型与一般的attention模型的区别。
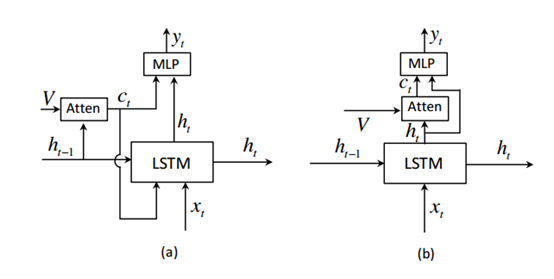
首先是从使用上一个状态变为了使用当前状态,而且更新LSTM状态的时候不再使用图片信息。另外加入了visual sentinel信息。
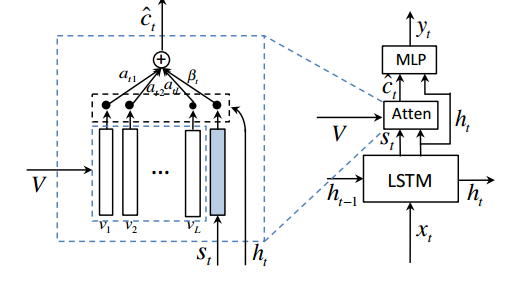
visual sentinel向量可以利用LSTM的状态、输入以及记忆 计算得到。
计算得到。
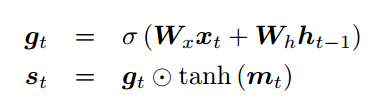
2.3加入语义特征的模型
这篇文章[4]以一种更加直接的方式来表示图像中的语义方式,而之前的模型中的encoder产生的向量采用的是隐式表示,不如这篇文章这么直接。
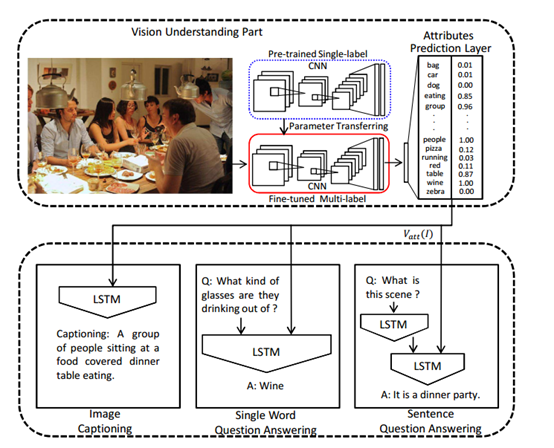
首先图片的语义表示是一个向量,向量中的每个位置对应的一个单词,对应着实体(名词)、动作(动词)、属性(形容词)语义信息。在生成这个向量的过程中,使用多标签分类模型,即每个图片可能同时对应多个标签。
首先进行预训练,利用数据集中的caption,提取高频单词作为向量中对应的单词。图片对应的caption单词作为相应的标签,利用element-wise logistic loss作为损失函数。
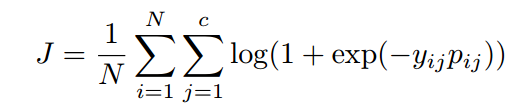
而在训练caption模型过程中,对参数进一步优化。假设,从图片生成的语义向量的函数为 (注意这里的att表示的attribute,不是attention),那么生成caption函数为:
(注意这里的att表示的attribute,不是attention),那么生成caption函数为:
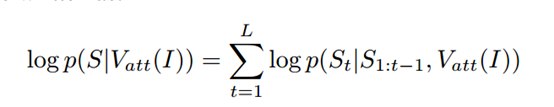
2.4脑海图片生成
这个模型[5]认为,人类在阅读一个句子的时候,脑海中会生成相应的图片。有时候,甚至我们忘记了相应的句子,但是脑海中的图片依然记得。

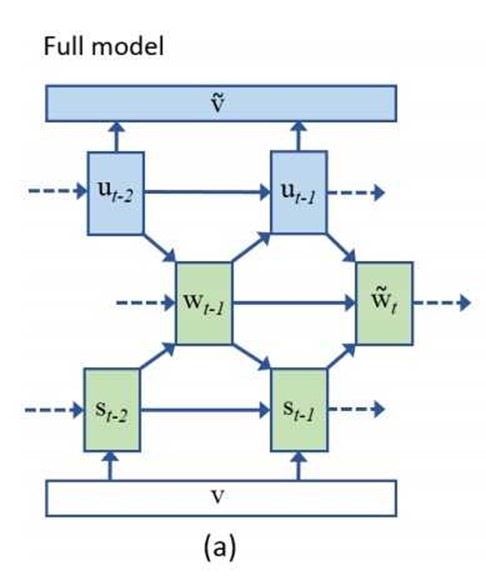
因此,模型采用的是图片标题生成与文本生成图片的多任务学习模型。在生成标题过程中维护一个向量 ,从该向量重建相应的图片特征向量表示。模型的目标函数不仅包括生成的标题,另外,重建的图片特征也要尽量接近于原始图片特征。
,从该向量重建相应的图片特征向量表示。模型的目标函数不仅包括生成的标题,另外,重建的图片特征也要尽量接近于原始图片特征。
2.5 From Captions to Visual Concepts and Back
这篇文章[6]同样是从图片中提取语义特征,不是encode-decoder的框架。文章提取语义特征采用的是多示例学习的方式。
多示例学习实际是一种半监督算法。考虑这样一种训练数据:我们有很多个数据包(bag),每个数据包中有很多个示例(instance)。我们只有对bag的正负类标记,而没有对instance的正负例标记。当一个bag被标记为正时,这个包里一定有一个instance是正类,但也有可能其他instance是负类,当一个bag被标记为负类时,它里面的所有instance一定是负类。
对应于图片,图片中的不同区域作为bag,而每个区域都是一个instance,而对应的单词则是标签。训练过程进行两步迭代,目标是训练一个模型给定一个区域,来判断该区域是否对应于某个标签,第一步是利用当前模型,选出正例bag中最有可能是正例的instance(即对应于单词的那个区域)、以及负例bag的instance(图片中的所有区域都是负样本),这样就完成了数据集的构建;第二步是利用选出的instance进行训练,更新模型。这样迭代下去,就可以对图片的区域进行分类了。这样我们就可以从图片的区域中提取所需要的单词。

提取单词后使用传统的统计语言模型进行句子生成。
2.6基于强化学习的模型
基于强化的模型主要是对文本生成过程进行优化[7]。将文本生成看成一个决策过程,每个时刻生成单词都是一个action,而对于生成序列的质量评估可以看成value。生成文本序列的评估指标作为reward,例如CIDEr。使用强化学习的好处在于可以直接利用不可微分的评价指标作为优化目标。另外,在训练过程中,生成序列的时候,通常采用的是上一时刻单词的ground-truth,而测试过程中又只能使用模型自己生成的上一时刻单词,即使用teacher-forcing的策略。这会造成exposure bias的问题。
假设从策略中采样的单词序列是 ,利用策略梯度算法进行优化:
,利用策略梯度算法进行优化:
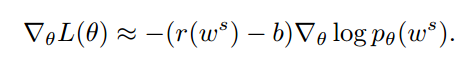
这里的b是一个baseline,它不影响梯度的计算,但是可以减少variance。r是reward, 是策略中产生该单词序列的概率。
是策略中产生该单词序列的概率。
文章提出了一个SCST(self-critical sequence training)算法,
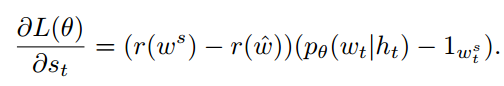
这里的baseline采用的是测试过程使用的算法产生序列的reward,例如使用greedy decoding。
另一篇文章[8],则采用的是visual-semantic embedding作为reward,通过训练一个模型,将文本、图像映射到同一个embedding空间。然后将图像embedding与文本embedding的cosine相似度作为reward。
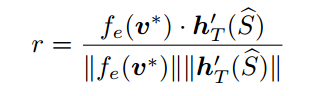
这里 、
、 分别是图片与文本的embedding函数。
分别是图片与文本的embedding函数。
训练使用的是actor-critic算法:
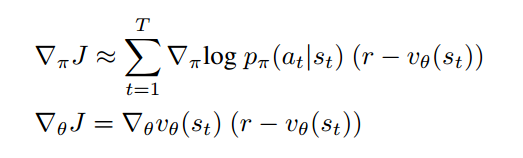
 是价值网络,作为reward的动态baseline。
是价值网络,作为reward的动态baseline。
当采用beam search进行解码的时候,通过结合策略 、与value估计来计算一个单词的得分。
、与value估计来计算一个单词的得分。
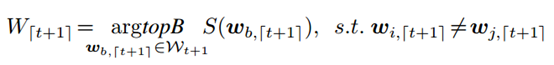
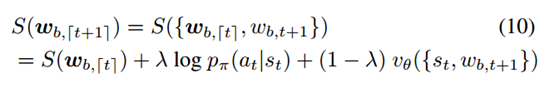
3一些结果
以NIC为例,看看caption模型的效果。
图片1

图片2

首先比较一下不同step的时候,模型产生的标题。
|
step |
Loss |
生成结果 |
|
1000 |
4 |
图片1 0) a man on a skateboard on a field . (p=0.000003) 1) a man riding a skateboard on a field . (p=0.000002) 2) a man on a skateboard on a bench . (p=0.000001) 图片2 0) a group of people standing on a field . (p=0.000026) 1) a group of people standing on a field (p=0.000012) 2) a group of people standing on a bench . (p=0.000011) |
|
10000 |
3 |
图片1 0) a woman is talking on a cell phone . (p=0.000784) 1) a woman is talking on a cell phone (p=0.000752) 2) a woman holding a cell phone while standing on a sidewalk . (p=0.000013) 图片2 0) a woman sitting on a chair with her umbrella . (p=0.000018) 1) a woman sitting on a chair with her umbrella (p=0.000012) 2) a woman sitting on a bench with a dog . (p=0.000010) |
|
100000 |
1 |
图片1 0) a man wearing a hat and sunglasses talking on a cell phone . (p=0.000191) 1) a woman wearing a hat and sunglasses talking on a cell phone . (p=0.000158) 2) a man wearing a hat and sunglasses talking on a cell phone (p=0.000024) 图片2 0) a young girl wearing a dress shirt and tie . (p=0.000044) 1) a young girl wearing a dress shirt and tie (p=0.000013) 2) a young girl wearing a dress shirt and a tie . (p=0.000007) |
在训练的初期,模型输出的结果非常的单一,以至于两个图片都是类似的描述。而到了后期,模型逐渐可以区分man和women,以及一些描述词语young。而且可以看出随着训练的进行,产生的标题越来越流畅。
4总结
Caption的一些模型还是十分精彩,而且caption任务本身也很酷。可以看出目前的主流是encoder-decoder框架,最新的一些研究通过改进框架、使用了强化学习来提升效果。
参考:
[1] Vinyals, Oriol, et al. “Show and tell: A neural image caption generator.”?Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[1+] Vinyals, Oriol, et al. “Show and tell: Lessons learned from the 2015 mscoco image captioning challenge.”?IEEE transactions on pattern analysis and machine intelligence?39.4 (2017): 652-663.
代码:https://github.com/tensorflow/models/tree/master/research/im2txt
https://github.com/KranthiGV/Pretrained-Show-and-Tell-model
[2] Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” International Conference on Machine Learning. 2015.
代码:https://github.com/jazzsaxmafia/show_attend_and_tell.tensorflow
[3] Lu, Jiasen, et al. “Knowing when to look: Adaptive attention via A visual sentinel for image captioning.”?arXiv preprint arXiv:1612.01887?(2016).
代码:https://github.com/jiasenlu/AdaptiveAttention
[4] Wu, Qi, et al. “What value do explicit high level concepts have in vision to language problems?.”?Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[5] Chen, Xinlei, and C. Lawrence Zitnick. “Mind’s eye: A recurrent visual representation for image caption generation.”?Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[6] Fang, Hao, et al. “From captions to visual concepts and back.”?Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[7] Rennie, Steven J., et al. “Self-critical sequence training for image captioning.”?arXiv preprint arXiv:1612.00563?(2016).
[8] Ren, Zhou, et al. “Deep Reinforcement Learning-based Image Captioning with Embedding Reward.”?arXiv preprint arXiv:1704.03899?(2017).